
第 4 章 抽象:进程
进程就是运行中的程序。
OS 通过虚拟化 CPU 来提供几乎有无数个 CPU 可用的假象。一个进程只运行一个时间片,然后切换到其它进程,这就是时分共享 CPU 技术。
要实现 CPU 的虚拟化,OS 就需要一些低级机制以及一些高级智能。
机制是一些低级方法或协议,例如上下文切换,它让 OS 停止运行一个程序并开始在给定 CPU 上运行另一个程序。
在机制之上,OS 中有一些智能以策略的形式存在。策略是在 OS 内作出某种决定的算法,例如对多个程序选择一个运行的调度策略。
4.1 抽象:进程概念
OS 为正在运行的程序提供的抽象,就是进程。
进程的机器状态,指程序在运行时可以读取或更新的内容,包括内存和寄存器。
4.2 进程 API
- 创建:创建新进程。
- 销毁:强制销毁进程。
- 等待:等待进程停止运行。
- 其它控制:例如暂停和恢复。
- 状态:获取进程状态信息。
4.3 进程创建
将代码和静态数据(如初始化变量)加载到内存中。程序最初以可执行格式驻留在磁盘上,OS 从磁盘读取这些字节并放到内存中。
早期 OS 中,加载在程序运行前全部完成,现代 OS 使用惰性加载,即只在程序执行时加载所需的代码或数据片段,这是通过分页和交换机制实现的。
OS 为程序的运行时栈分配内存。例如 C 程序使用栈存放局部变量、函数参数和返回地址。OS 可能会初始化栈,例如为
main()函数填入argc和argv参数。OS 也可能为程序分配堆内存。在 C 中调用
malloc()申请空间,free()释放。OS 执行一些初始化任务,尤其是 I/O 相关任务。例如 UNIX 默认每个进程都有 3 个打开的文件描述符:标准输入、输出和错误。
OS 启动程序,在入口处运行,即
main()。通过跳转到main()例程,OS 将 CPU 控制权转移到新创建的进程中。
4.4 进程状态
- 运行
- 就绪
- 阻塞
![]()
4.5 数据结构
//PAGEBREAK: 17
// Saved registers for kernel context switches.
// Don't need to save all the segment registers (%cs, etc),
// because they are constant across kernel contexts.
// Don't need to save %eax, %ecx, %edx, because the
// x86 convention is that the caller has saved them.
// Contexts are stored at the bottom of the stack they
// describe; the stack pointer is the address of the context.
// The layout of the context matches the layout of the stack in swtch.S
// at the "Switch stacks" comment. Switch doesn't save eip explicitly,
// but it is on the stack and allocproc() manipulates it.
struct context {
uint edi;
uint esi;
uint ebx;
uint ebp;
uint eip;
};
enum procstate { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};context 结构体是寄存器上下文。进程停止时,将寄存器内容保存到内存,进程恢复时,将内容取回到寄存器。这种技术叫上下文切换。
procstate 用于表示进程状态。
ZOMBIE 称为僵尸状态,表示进程处于已退出但尚未清理的最终状态。这个状态可用于其他进程(通常是父进程)检查进程的返回代码。完成后,父进程将进行最后一次调用(如 wait())以等待子进程完成,并告诉 OS 可以清理这个进程的数据结构。
proc 结构体是 PCB(进程控制块)。
第 5 章 进程 API
5.1 fork() 系统调用
fork() 是 OS 提供的创建新进程的方法。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int
main(int argc, char *argv[])
{
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) {
// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
} else {
// parent goes down this path (original process)
printf("hello, I am parent of %d (pid:%d)\n",
rc, (int) getpid());
}
return 0;
}
$ ./p1
hello world (pid:29146)
hello, I am child (pid:29147)
hello, I am parent of 29147 (pid:29146)
新创建的进行几乎与调用的进程完全一样,在 OS 看来就好像有两个 p1 的副本在运行,两者都将从 fork() 系统调用返回。
但子进程不会从 main() 函数开始执行,而是紧接着 fork() 之后。父进程获得的返回值是子进程的 PID,子进程获得的返回值是 0。这样就可以在编码中处理两种不同的情况。
子进程和父进程的先后顺序是不确定的。
5.2 wait() 系统调用
有时父进程需要等待子进程执行完毕,此时可以用 wait() 或 waitpid() 系统调用。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int
main(int argc, char *argv[])
{
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) {
// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
sleep(1);
} else {
// parent goes down this path (original process)
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
rc, wc, (int) getpid());
}
return 0;
}
$ ./p2
hello world (pid:29266)
hello, I am child (pid:29267)
hello, I am parent of 29267 (rc_wait:29267) (pid:29266)
5.3 exec() 系统调用
exec() 系统调用可以让子进程执行与父进程不同的程序。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int
main(int argc, char *argv[])
{
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) {
// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
char *myargs[3];
myargs[0] = strdup("wc"); // program: "wc" (word count)
myargs[1] = strdup("p3.c"); // argument: file to count
myargs[2] = NULL; // marks end of array
execvp(myargs[0], myargs); // runs word count
printf("this shouldn't print out");
} else {
// parent goes down this path (original process)
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
rc, wc, (int) getpid());
}
return 0;
}
这里在子进程中调用 wc p3.c 来统计字符数(源码与书中不同,因此结果不同):
$ ./p3
hello world (pid:29383) hello, I am child (pid:29384)
29 107 1030 p3.c
hello, I am parent of 29384 (rc_wait:29384) (pid:29383)
exec() 会从可执行程序中加载代码和静态数据,并覆盖自身,堆栈等内存空间也会初始化,然后 OS 执行该程序,将参数传递给该进程。
exec() 不会创建新进程,而是用当前程序替换。exec() 成功调用后不会返回。
5.4 为什么这样设计 API
将 fork() 与 exec() 分离,可以在 fork() 之后、exec() 之前运行一些代码,例如改变环境,从而实现特定功能。
shell 也是一个用户程序。当运行一个命令时,shell 先在文件系统中找到这个可执行程序,调用 fork() 创建新进程,并调用 exec() 来执行它,调用 wait() 来等待该命令完成。子进程执行结束后,shell 从 wait() 返回,等待用户输入下一条命令。
例如,
$ wc p3.c > newfile.txt
wc 的输出结果被重定向到 newfile.txt 中,shell 实现的方式为,当创建子进程后,在调用 exec() 之前先关闭标准输出,打开文件 newfile.txt,这样 wc 的输出结果就被发送到该文件。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <assert.h>
#include <sys/wait.h>
int
main(int argc, char *argv[])
{
int rc = fork();
if (rc < 0) {
// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child: redirect standard output to a file
close(STDOUT_FILENO);
open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
// now exec "wc"...
char *myargs[3];
myargs[0] = strdup("wc"); // program: "wc" (word count)
myargs[1] = strdup("p4.c"); // argument: file to count
myargs[2] = NULL; // marks end of array
execvp(myargs[0], myargs); // runs word count
} else {
// parent goes down this path (original process)
int wc = wait(NULL);
assert(wc >= 0);
}
return 0;
}
UNIX 管道也是用类似方式实现的,但用的是 pipe() 系统调用。一个进程的输出被连接到一个内核管道上(如队列),另一个进程的输入也被连接到同一管道上,因此前一个进程的输出无缝作为后一个进程的输入。例如 grep -o foo file | wc -l。
5.5 其他 API
UNIX 还有其他与进程交互的方式,如 kill() 系统调用可以向进程发送信号,要求其睡眠、终止等。
作业
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int x = 100;
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
printf("child, pid=%d, x=%d\n", getpid(), x);
x = 10;
printf("child, pid=%d, x=%d\n", getpid(), x);
} else {
printf("parent, pid=%d, x=%d\n", getpid(), x);
x = 1;
printf("parent, pid=%d, x=%d\n", getpid(), x);
}
return 0;
}#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd = open("./p2.output", O_CREAT | O_WRONLY | O_TRUNC, 0644);
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
write(fd, "child\n", 6);
} else {
write(fd, "parent\n", 7);
}
return 0;
}#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
printf("hello\n");
} else {
wait(NULL);
printf("goodbye\n");
}
return 0;
}int execl(char const *path, char const *arg0, ...);
int execle(char const *path, char const *arg0, ..., char const *envp[]);
int execlp(char const *file, char const *arg0, ...);
int execv(char const *path, char const *argv[]);
int execve(char const *path, char const *argv[], char const *envp[]);
int execvp(char const *file, char const *argv[]);
e – An array of pointers to environment variables is explicitly passed to the new process image.
l – Command-line arguments are passed individually (a list) to the function.
p – Uses the PATH environment variable to find the file named in the file argument to be executed.
v – Command-line arguments are passed to the function as an array (vector) of pointers.
e:environment variables,指定环境变量。l:list,通过列表传递参数。p:PATH environment variable,即PATH环境变量,从PATH中查找可执行程序。v:vector,通过数组传递参数。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main() {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// printf("execl\n");
// execl("/bin/ls", "/bin/ls", (char *) NULL);
// printf("execlp\n");
// execlp("ls", "ls", (char *) NULL);
// printf("execv\n");
// char *cvargs[2];
// cvargs[0] = strdup("/bin/ls");
// cvargs[1] = NULL;
// execv(cvargs[0], cvargs);
printf("execvp\n");
char *cvpargs[2];
cvpargs[0] = strdup("ls");
cvpargs[1] = NULL;
execvp(cvpargs[0], cvpargs);
} else {
}
return 0;
}- 父进程调用
wait()返回的是子进程的pid,子进程调用wait()返回值为-1:
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
int wc = wait(NULL);
printf("child, pid=%d, wc=%d\n", getpid(), wc);
} else {
int wc = wait(NULL);
printf("parent, pid=%d, wc=%d\n", getpid(), wc);
}
return 0;
}wait(&wstatus)等价于waitpid(-1, &wstatus, 0):
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
printf("child, pid=%d\n", getpid());
} else {
int wc = waitpid(-1, NULL, 0);
printf("parent, pid=%d, wc=%d\n", getpid(), wc);
}
return 0;
}- 关闭标准输出后,
printf()不会有内容输出:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
close(STDOUT_FILENO);
printf("child, pid=%d\n", getpid());
} else {
printf("parent, pid=%d\n", getpid());
}
return 0;
}- 使用
pipe()系统调用创建管道,使用dup2()系统调用将标准输入和输出重定向到管道两端:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int pipefd[2];
if (pipe(pipefd) != 0) {
fprintf(stderr, "pipe failed\n");
exit(1);
}
int i, rc;
for (i = 0; i < 2; ++i)
if ((rc = fork()) == 0) break;
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
printf("child, pid=%d, i=%d\n", getpid(), i);
if (i == 0) {
// writer
dup2(pipefd[1], STDOUT_FILENO);
close(pipefd[0]);
close(pipefd[1]);
printf("writer\n");
} else {
// reader
dup2(pipefd[0], STDIN_FILENO);
close(pipefd[0]);
close(pipefd[1]);
char buf;
while (read(STDIN_FILENO, &buf, 1) > 0)
write(STDOUT_FILENO, &buf, 1);
}
} else {
printf("parent, pid=%d\n", getpid());
}
return 0;
}int dup2(int oldfd, int newfd);
dup2() 将 newfd 指向 oldfd,如果 newfd 已经打开,则首先会被关闭,然后再指向 oldfd。这样在访问 newfd 时,实际上访问的是 oldfd。
reader 进程中最后 3 行是读取标准输入并输出,如果将其注释,则不会有 writer 输出,可见实现了将一个进程的标准输出连接到另一个进程的标准输入。
第 6 章 机制:受限直接执行
6.1 基本技巧:受限直接执行
如果直接在 CPU 上执行程序,会有两个问题:
- OS 如何确保程序不做任何我们不希望它做的事?
- OS 如何实现虚拟化 CPU,即时分共享?
6.2 问题 1:受限制的操作
例如,如果用户进程可以任意访问磁盘 I/O,那么文件系统权限保护就会失效。为此必须引入新的处理器模式。
- 用户模式:用户模式下运行的代码会受到限制,例如无法发起 I/O 请求,这样会导致处理器异常,OS 可能会终止该进程。
- 内核模式:OS 以这种模式运行,运行代码可以任意进行特权操作,如发起 I/O 请求、使用受限指令等。
如果用户希望执行某种特权操作,现代硬件提供了用户程序执行系统调用的能力,系统调用允许内核向用户程序暴露某些关键功能,如访问文件系统、创建和销毁进程、与其他进程通信、分配内存等。
要执行系统调用,程序必须执行特殊的陷阱指令,该指令跳入内核,并将特权级别提升到内核模式。完成工作后,OS 调用特殊的从陷阱返回指令,返回到发起调用的用户程序中,同时回到用户模式。
执行陷阱指令时,硬件需要将调用者的寄存器保存起来,以便在 OS 发出从陷阱指令时正确返回。例如,在 x86 上,处理器会将程序计数器、标志和其他一些寄存器送入每个进程的内核栈。从陷阱返回时,从栈弹出这些值,并恢复执行用户程序。
系统调用看起来就像过程调用,实际上系统调用就是将陷阱指令隐藏在过程调用中。C 库中的系统调用部分是用汇编手工编码的。
陷阱如何知道在 OS 内运行哪些代码?显然不应该由用户程序指定。这是由陷阱表来实现的。
机器启动时在内核模式下执行,根据需要配置机器硬件,设置陷阱表。OS 首先做的事之一,就是告诉硬件在发生异常事件时要运行哪些代码。
当发生中断时,OS 通常通过某种特殊指令,通知硬件这些陷阱处理程序的位置。一旦硬件被通知,它就会记住这些处理程序的位置,直到重启。这种指令也是特权操作。
假设每个进程都有一个内核栈,用于在进入和离开内核时,保存和恢复寄存器:
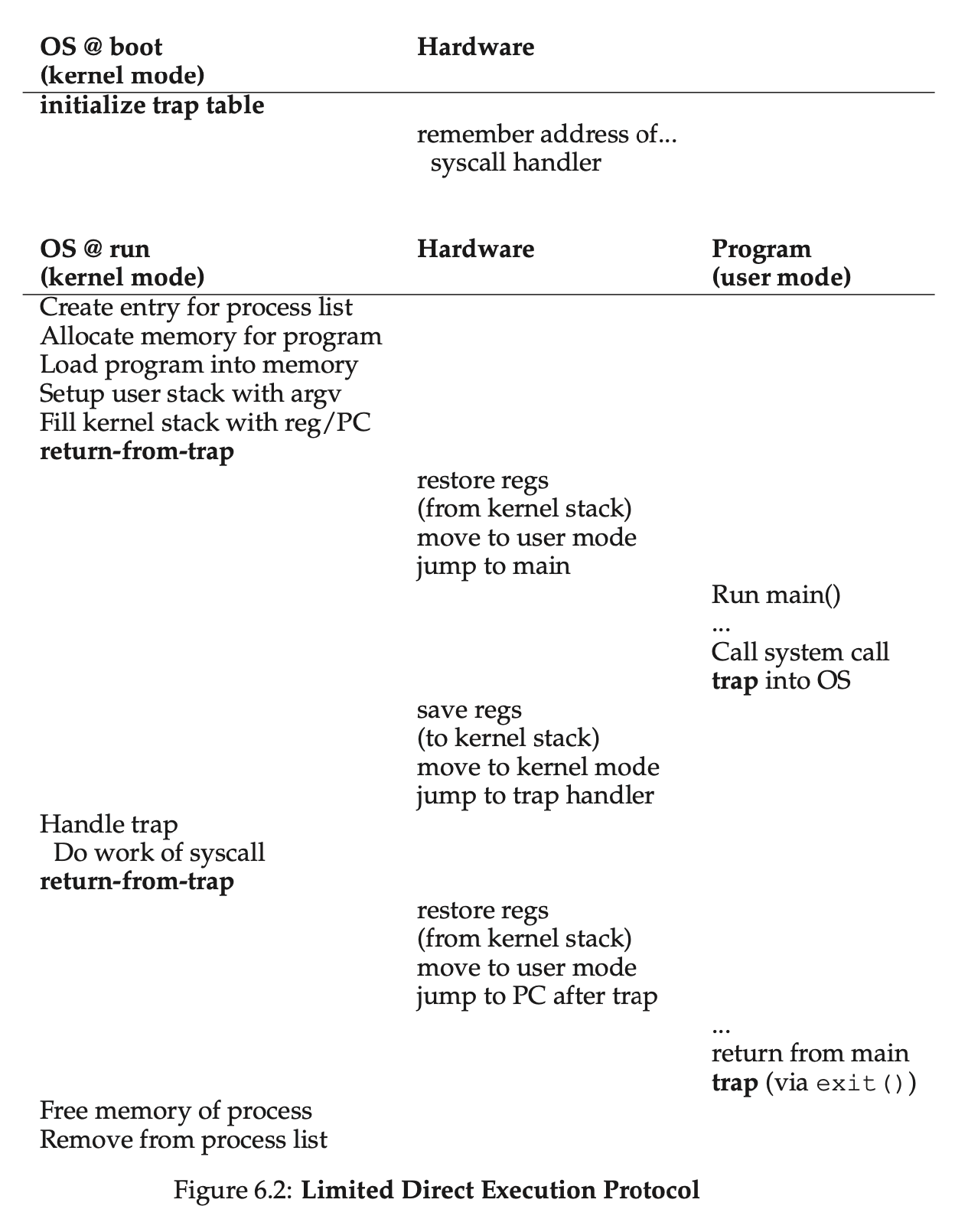
LDE 协议(Limited Direct Excution Protocol,受限直接执行协议)有两个阶段:
- 系统启动时,内核初始化陷阱表,并且 CPU 记住它的位置。内核通过特权指令执行此操作。
- 运行进程时,内核设置一些内容,然后使用从陷阱返回指令,将 CPU 切换到用户模式并开始运行该进程。进程发出系统调用时,会重新陷入 OS,OS 处理完成后再次通过从陷阱返回指令,返回进程。进程完成工作后,从
main()返回,然后通过exit()系统调用等方式陷入 OS。OS 清理干净,至此完成。
6.3 问题 2:在进程之间切换
OS 实现进程之间的切换,但进程在 CPU 运行时,意味着 OS 不在运行,于是有了问题:如何让 OS 重新获得 CPU 控制权,以便实现进程切换?
协作方式:等待系统调用
早期 OS 采用这种方式,OS 相信进程会合理运行,假定运行时间长的进程会定期放弃 CPU。
大多数进程通过系统调用将 CPU 控制权交给 OS。这样的 OS 通常包括一个显式的 yield 系统调用,它除了移交控制权外什么都不做。
如果进程执行了非法操作,也会将控制权交给 OS。例如将 0 作为除数,或访问应该无法访问的内存,就会陷入 OS。OS 再次控制 CPU,且可能会终止该进程。
这种方式可能造成 CPU 一直被进程占用。
非协作方式:操作系统进行控制
如果进程不协作,OS 通过时钟中断获取 CPU 控制权。
时钟设备可以编程为每隔几毫秒产生一次中断。产生中断时,当前正在运行的进程停止,OS 中预先配置的中断处理程序会运行,OS 重新获得 CPU 控制权。
首先,就像系统调用一样,OS 必须通知硬件在时钟中断发生时运行哪些代码,这是在启动时完成的。
其次,在启动过程中,OS 必须启动时钟,这是特权操作。
一旦时钟开始,OS 就可以自由运行用户程序了,因为控制权最终会归还给它。时钟也可以关闭,这也是特权操作。
与显式系统调用陷入内核时相似,发生时钟中断时,硬件需要保存进程的状态如寄存器,执行从陷阱返回指令时再恢复。
保存和恢复上下文
当 OS 重新获取控制权后,必须决定是继续运行当前的进程,还是切换到另一个进程,将由调度程序通过调度策略作出决定。调度程序是 OS 的一部分。
上下文切换:OS 执行底层汇编代码,保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复另一个进程的寄存器及内核栈指针。
进程 A 正在运行,然后被切换到进程 B 的简略过程:
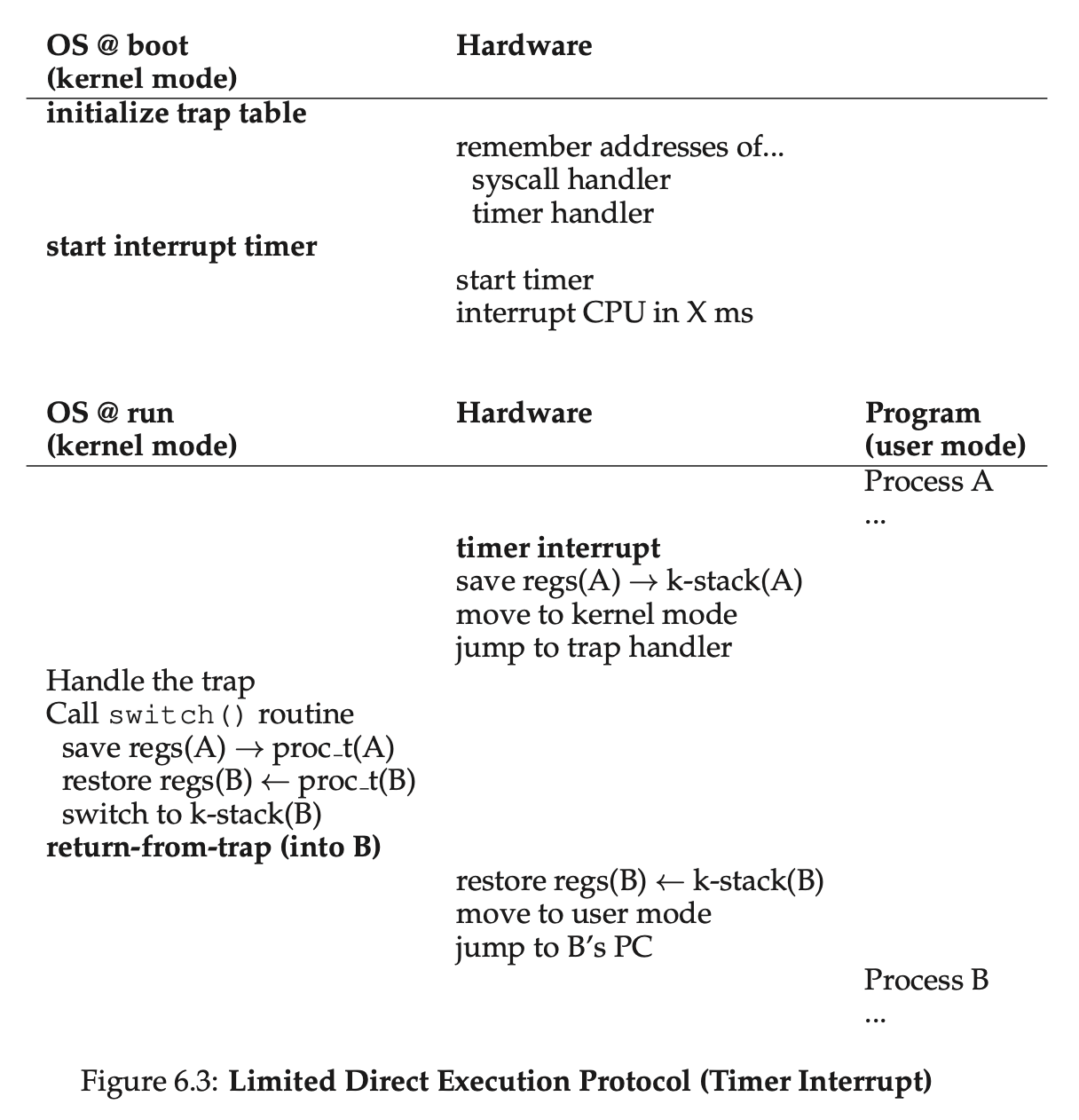
书中的图不是很恰当,看上去是直接把 A 切换到 B。
xv6 上下文其实就是 context 结构体:
//PAGEBREAK: 17
// Saved registers for kernel context switches.
// Don't need to save all the segment registers (%cs, etc),
// because they are constant across kernel contexts.
// Don't need to save %eax, %ecx, %edx, because the
// x86 convention is that the caller has saved them.
// Contexts are stored at the bottom of the stack they
// describe; the stack pointer is the address of the context.
// The layout of the context matches the layout of the stack in swtch.S
// at the "Switch stacks" comment. Switch doesn't save eip explicitly,
// but it is on the stack and allocproc() manipulates it.
struct context {
uint edi;
uint esi;
uint ebx;
uint ebp;
uint eip;
};xv6 上下文切换1,实际上是先将原进程上下文切换到当前 CPU 的 scheduler(也是 context 结构体),然后再切换到新进程。

调用 swtch() 时,栈顶元素分别为:
%eip:调用时自动将其下一条指令地址压栈。- CPU 的
scheduler:指向一个context结构体。 - 原进程的
context的指针(注意这里变量与结构体同名):指针的指针,这是为了能修改原进程的context指向。
上下文切换代码(书中使用的是旧版,故不一致):
# Context switch
#
# void swtch(struct context **old, struct context *new);
#
# Save the current registers on the stack, creating
# a struct context, and save its address in *old.
# Switch stacks to new and pop previously-saved registers.
.globl swtch
swtch:
movl 4(%esp), %eax
movl 8(%esp), %edx
# Save old callee-saved registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp
# Load new callee-saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
swtch() 首先将 old 和 new 分别保存到 %eax 和 %edx,然后将其余寄存器入栈:
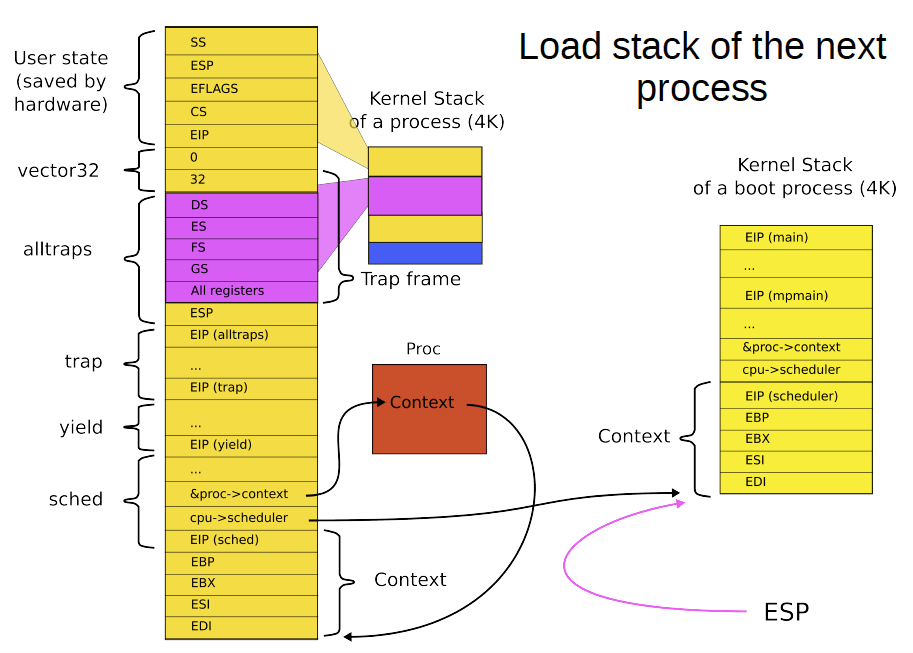
这样栈顶元素与 context 结构体完全一致。
接着 movl %esp, (%eax) 将 *old(即原进程的 context)指向栈顶,相当于 &p->context = %esp,然后 movl %edx, %esp 将栈指针切换为 new(即 scheduler)。
最后从栈顶依次弹出寄存器(顺序与入栈相反)。
之后再选择合适的新进程,使用 swtch() 切换其上下文。
作业
测试环境:物理机为搭载 i7-7700HQ 的 MacBook Pro 2017,使用 VMware 运行 Debian 10.8,分配一个 CPU 核心。
测量系统调用开销:
#include <fcntl.h>
#include <stdio.h>
#include <sys/time.h>
#include <unistd.h>
int main() {
int fd = open("/dev/null", O_RDONLY);
char buf;
int i = 0, n = 1000000;
struct timeval start, end;
gettimeofday(&start, NULL);
for (; i < n; ++i) {
read(fd, &buf, 0);
}
gettimeofday(&end, NULL);
long us =
(end.tv_sec - start.tv_sec) * 1000000 + end.tv_usec - start.tv_usec;
printf("%ld ns\n", us * 1000 / n);
return 0;
}Debian 虚拟机上的结果比物理机还要少:
417 ns
测量上下文切换开销:
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <unistd.h>
int main() {
int pfd1[2], pfd2[2];
if (pipe(pfd1) != 0 || pipe(pfd2) != 0) {
fprintf(stderr, "pipe failed\n");
exit(1);
}
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
exit(1);
}
char buf1, buf2;
int i = 0, n = 100000;
if (rc == 0) {
close(pfd1[1]);
close(pfd2[0]);
for (; i < n; ++i) {
read(pfd1[0], &buf1, 1);
write(pfd2[1], &buf2, 1);
}
} else {
close(pfd1[0]);
close(pfd2[1]);
struct timeval start, end;
gettimeofday(&start, NULL);
for (; i < n; ++i) {
write(pfd1[1], &buf1, 1);
read(pfd2[0], &buf2, 1);
}
gettimeofday(&end, NULL);
long us = (end.tv_sec - start.tv_sec) * 1000000 + end.tv_usec -
start.tv_usec;
printf("%ld ns\n", us * 1000 / 2 / n);
}
return 0;
}这里有两个进程,两个管道,父进程向其中一个管道写入,从另一个读取,子进程相反。
在一次循环中,父进程写入后等待读取,故阻塞,子进程读取并写入,再次等待读取,故阻塞,切换回父进程。因此一次循环有两次上下文切换。
由于只分配一个核心,不用考虑多核的问题,否则需要把进程绑定到同一核心。Linux 上使用 sched_setaffinity() 系统调用来实现。
测试结果:
1911 ns
这一结果可能不准确,因为其他进程也运行在同一核心。
但一般的进程在切换上下文时,还要切换 Cache、TLB 等,开销会更大。
第 7 章 进程调度:介绍
7.2 调度指标
$$T_{周转时间} = T_{完成时间} - T_{到达时间}$$
7.3 先进先出(FIFO)
即先来先服务(FCFS),非抢占式。
7.4 最短作业优先(SJF)
非抢占式,要求作业同时到达且时间已知。
7.5 最短完成时间优先(STCF)
即抢占式 SJF,每当新作业到达,选择剩余时间最短的进行调度。
7.6 新度量指标:响应时间
$$T_{响应时间} = T_{首次运行} - T_{到达时间}$$
7.7 轮转
轮转调度:在一个时间片内运行一个作业,然后切换到下一个,反复执行。
时间片长度必须是时钟中断周期的倍数。上下文切换的开销不仅来自寄存器,还有 Cache、TLB、分支预测器等硬件,必须权衡时间片长度。
周转时间长,响应时间短。
7.8 结合 I/O
调度程序在作业发起 I/O 请求时将其阻塞,切换到另一个作业,在 I/O 完成时将其由阻塞变为就绪。
第 8 章 调度:多级反馈队列(MLFQ)
目标是优化周转时间、降低响应时间。
8.1 两条基本原则
- 规则 1:只运行高优先级作业,较低级作业不会运行。
- 规则 2:作业优先级相等,则轮转运行。
8.2 改变优先级
- 规则 3:作业开始时放在最高优先级。
- 规则 4a:作业用完时间片后,降低其优先级(移入下一级队列)。
- 规则 4b:如果作业在其时间片内主动释放 CPU,则优先级不变。
这样就假定作业是短作业,如果确实是短作业则会很快执行完毕,否则移入低优先级,这时 MLFQ 类似 SJF。
如果有 I/O,则对于大量 I/O 操作(如用户键盘交互)的作业,根据规则 4b,优先级不变,会很快得到响应,可见对交互型作业也有利。
存在的问题:
- 如果短作业过多,则长作业会长时间得不到 CPU 而饥饿。
- 程序可能在一段时间内表现为计算密集型,一段时间表现为交互型。
- 程序可以模拟 I/O 主动放弃 CPU 来欺骗调度程序,长时间占用 CPU。
8.3 提升优先级
为解决问题 1 和 2,增加新规则:
- 规则 5:每过一段时间 S,就将系统中所有作业重新加入最高优先级队列。
8.4 计时方式
为解决问题 3,重写规则 4a 和 4b:
- 规则 4:一旦作业用完在其队列对应的时间配额,则移入下一队列。
8.5 其他问题
- 应配置多少队列?
- 每一级队列时间片多大?
- 每过多久提升一次优先级(巫毒常量应为多大)?
应避免设置巫毒常量,例如可以让系统自己去学习一个合适的值。
第 9 章 调度:比例份额
比例份额调度又称公平份额调度,其目标是确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响应时间。
9.1 彩票调度
每个进程拥有一定彩票数,其占系统总彩票数的百分比,就是其占用资源的份额。相当于权重。
彩票调度按照彩票数,概率性选择进程来运行。
这其中利用了随机性,至少有 3 点优势:
- 避免奇怪的边角情况。例如 LRU 算法可能在有重复序列的情况下表现很差。
- 轻量,几乎无需记录状态,只需记录彩票数。
- 快速。
如何分配彩票数是关键问题。
9.6 步长调度
由于采用了随机性,彩票调度在作业较短的情况下可能不会产生正确的比例。
步长调度是确定性的比例分配算法。
每个进程有一个步长和行程,步长与彩票数成反比。每次选择行程最小的运行,运行后行程值增加一个步长。
彩票调度的优势在于,不需要记录这些全局状态。而且步长调度初始行程值也难以设置,如果设置为 0 的话就会长时间独占 CPU 了,而彩票调度无需考虑。
9.7 小结
比例份额没有广泛使用,主要因为:
- 不能很好地适应 I/O。
- 彩票数如何分配是个问题。
Linux 完全公平调度(CFS)
CFS(Completely Fair Scheduler,完全公平调度)2中文版没有介绍。
CFS 设定一个调度周期 sched_latency,CPU 运行的所有进程平均分配这个周期。这里分配的时间片不是绝对平均的,而是加权的虚拟运行时间。
调度周期并不是无限可分的。当进程过多时,每个进程分配到的时间片就会过短,如果进程频繁切换,大量 CPU 时间被浪费在切换上,于是设定一个最小值 min_granularity,时间片不得小于这个值,同时调度周期也会变大。
时钟中断触发后,CFS 判断当前进程是否用完时间片,并进行切换。进程的时间片不一定是时钟周期的倍数,所以短期内可能不会被调度,但长期来看仍然是公平的。
对每个进程累积记录虚拟运行时间 vruntime,每次从当前 CPU 的运行进程中选择 vruntime 最小的进行调度。虚拟运行时间与实际运行时间成正比,与进程的权重成反比:
$$vruntime_i = vruntime_i + \frac{weight_0}{weight_i} \cdot runtime_i$$
$weight_0$ 是优先级为 0 的权重。优先级和权重的映射关系,记录在 prio_to_weight 数组中:
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
优先级从 -20 到 19,数值越大优先级越低,默认优先级为 0,即对于默认优先级进程来说,实际运行时间与虚拟运行时间相等。
权重数值经过设计,当两个进程优先级之差一定时,其权重的比例也基本一定。例如 $\frac {weight_{-5}}{weight_0} = \frac {weight_0}{weight_{10}}$,即 3121/1024 = 1024/335。
进程以 vruntime 为键(实际以 vruntime 与最小的 min_vruntime 之差为键,因为虚拟运行时间是无符号整数)存储在红黑树中。
此外还有一个问题,当有新进程运行或者休眠进程唤醒时,其 vruntime 远小于正在运行的老进程,就会造成老进程饥饿,这时就要以 min_vruntime 为基础将 vruntime 设置一个合适的值。
第 10 章 多处理器调度
将多个 CPU 组装在一块芯片上,这就是多核处理器。
在多处理器上工作主要有 3 个问题:
- 缓存一致性问题。由于将缓存数据写回内存较慢,其他 CPU 读取到的内存会不一致。通过监控内存访问(如总线窥探),每个缓存都监听所有缓存和内存的总线,来发现内存访问,如果数据被更新,则将本地副本废弃或更新。
- 同步问题。需要使用互斥原语(如锁)保证正确性。
- 缓存亲和度问题。将进程切换到不同 CPU 上时,缓存也要重新加载。应尽量使进程保持在同一个 CPU 上。
10.4 单队列多处理器调度 SQMS
简单复用单处理器调度的基本架构,将所有需要调度的作业放在一个单独的队列中,即单队列多处理器调度。
SQMS 的问题:
- 缺乏扩展性。SQMS 访问单个队列,如果通过加锁来保证原子性,那么 CPU 数量扩展越多,带来的性能损失越大。
- 缓存亲和度。需要引入一些亲和性机制,尽量让进程在同一个 CPU 上运行。在保持一些作业亲和度的同时,可能需要牺牲其他作业的亲和度来实现负载均衡。
10.5 多队列多处理器调度 MQMS
MQMS 每个 CPU 一个队列。具有良好的扩展性和缓存亲和度。
MQMS 存在负载不均的问题,部分 CPU 持续工作,部分 CPU 长时间闲置。需要通过迁移来实现负载均衡。
10.6 Linux 多处理器调度
O(1) 调度、CFS 调度采用多队列,前者类似 MLFQ,后者是确定的比例调度。
脑残调度(BFS 调度)采用单队列,也基于比例调度,适合交互性强的进程,例如桌面环境。